

导读:你是否使用像Siri或Alexa这样的个人助理客户端?你是否依赖垃圾邮件过滤器来保持电子邮件收件箱的干净?
本文用浅显易懂的语言精准概括了机器学习的相关知识,内容全面,总结到位,剖析了机器学习的what,who,when, where, how,以及why等相关问题。从机器学习的概念,到机器学习的发展史,再到机器学习的各类算法,最后到机器学习的最新应用,十分详尽。适合小白快速了解机器学习。

你是否使用像Siri或Alexa这样的个人助理客户端?你是否依赖垃圾邮件过滤器来保持电子邮件收件箱的干净?你是否订阅了Netflix,并依赖它惊人的准确推荐来发现新的电影可看?如果你对这些问题说“是”,恭喜你!你已经很好地利用了机器学习!
虽然这听起来很复杂,需要大量的技术背景,但机器学习实际上是一个相当简单的概念。为了更好地理解它,让我们研究一下关于机器学习的what,who,when, where, how,以及why。

每天5分钟快速玩转机器学习算法作者:幻风的AI之路-人要是没有梦想和神经网络有什么区别?8.88元 787人已购详情
什么是机器学习?
机器学习的核心是“使用算法解析数据,从中学习,然后对世界上的某件事情做出决定或预测”。这意味着,与其显式地编写程序来执行某些任务,不如教计算机如何开发一个算法来完成任务。有三种主要类型的机器学习:监督学习、非监督学习和强化学习,所有这些都有其特定的优点和缺点。
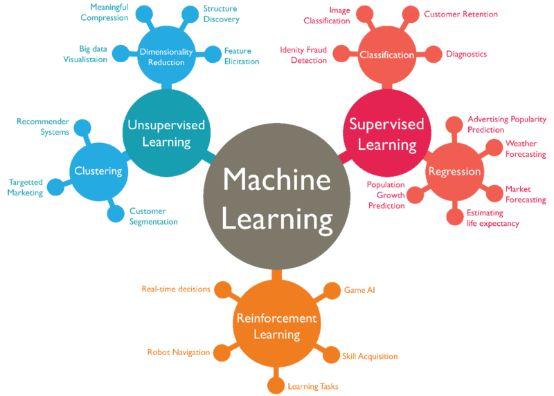
监督学习涉及一组标记数据。计算机可以使用特定的模式来识别每种标记类型的新样本。监督学习的两种主要类型是分类和回归。在分类中,机器被训练成将一个组划分为特定的类。分类的一个简单例子是电子邮件账户上的垃圾邮件过滤器。过滤器分析你以前标记为垃圾邮件的电子邮件,并将它们与新邮件进行比较。如果它们匹配一定的百分比,这些新邮件将被标记为垃圾邮件并发送到适当的文件夹。那些比较不相似的电子邮件被归类为正常邮件并发送到你的邮箱。
第二种监督学习是回归。在回归中,机器使用先前的(标记的)数据来预测未来。天气应用是回归的好例子。使用气象事件的历史数据(即平均气温、湿度和降水量),你的手机天气应用程序可以查看当前天气,并在未来的时间内对天气进行预测。
在无监督学习中,数据是无标签的。由于大多数真实世界的数据都没有标签,这些算法特别有用。无监督学习分为聚类和降维。聚类用于根据属性和行为对象进行分组。这与分类不同,因为这些组不是你提供的。聚类的一个例子是将一个组划分成不同的子组(例如,基于年龄和婚姻状况),然后应用到有针对性的营销方案中。降维通过找到共同点来减少数据集的变量。大多数大数据可视化使用降维来识别趋势和规则。
最后,强化学习使用机器的个人历史和经验来做出决定。强化学习的经典应用是玩游戏。与监督和非监督学习不同,强化学习不涉及提供“正确的”答案或输出。相反,它只关注性能。这反映了人类是如何根据积极和消极的结果学习的。很快就学会了不要重复这一动作。同样的道理,一台下棋的电脑可以学会不把它的国王移到对手的棋子可以进入的空间。然后,国际象棋的这一基本教训就可以被扩展和推断出来,直到机器能够打(并最终击败)人类顶级玩家为止。
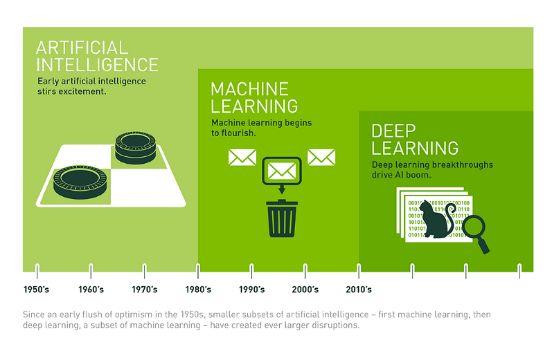
但是,等等,你可能会说。我们是在说人工智能吗?机器学习是人工智能的一个分支。人工智能致力于创造出比人类更能完成复杂任务的机器。这些任务通常涉及判断、策略和认知推理,这些技能最初被认为是机器的“禁区”。虽然这听起来很简单,但这些技能的范围非常大——语言处理、图像识别、规划等等。
机器学习使用特定的算法和编程方法来实现人工智能。没有机器学习,我们前面提到的国际象棋程序将需要数百万行代码,包括所有的边缘情况,并包含来自对手的所有可能的移动。有了机器学习,我们可以将代码量缩小到以前的一小部分。很棒对吧?
有一个缺失的部分:深度学习和神经网络。我们稍后会更详细地讨论它们,请注意,深度学习是机器学习的一个子集,专注于模仿人类大脑的生物学和过程。
谁发展了机器学习?何时何地?
A breakthrough in machine learning would be worth ten Microsofts.—Bill Gates
在我看来,机器学习最早的发展是Thomas Bayes 在1783年发表的同名理论,贝斯定理发现了给定有关类似事件的历史数据的事件的可能性。这是机器学习的贝叶斯分支的基础,它寻求根据以前的信息寻找最可能发生的事件。换句话说,Bayes定理只是一个从经验中学习的数学方法,是机器学习的基本思想。

几个世纪后,1950年,计算机科学家 Alan Turing发明了所谓的图灵测试,计算机必须通过文字对话一个人,让人以为她在和另一个人说话。图灵认为,只有通过这个测试,机器才能被认为是“智能的”。1952年,Arthur Samuel创建了第一个真正的机器学习程序——一个简单的棋盘游戏,计算机能够从以前的游戏中学习策略,并提高未来的性能。接着是Donald Michie 在1963年推出的强化学习的tic-tac-toe程序。在接下来的几十年里,机器学习的进步遵循了同样的模式--一项技术突破导致了更新的、更复杂的计算机,通常是通过与专业的人类玩家玩战略游戏来测试的。
它在1997年达到巅峰,当时IBM国际象棋电脑深蓝(Deep Blue)在一场国际象棋比赛中击败了世界冠军加里·卡斯帕罗夫(Garry Kasparov)。最近,谷歌开发了专注于古代中国棋类游戏围棋(Go)的AlphaGo,该游戏被普遍认为是世界上最难的游戏。尽管围棋被认为过于复杂,以至于一台电脑无法掌握,但在2016年,AlphaGo终于获得了胜利,在一场五局比赛中击败了Lee Sedol。
机器学习最大的突破是2006年的深度学习。深度学习是一类机器学习,目的是模仿人脑的思维过程,经常用于图像和语音识别。深度学习的出现导致了我们今天使用的(可能是理所当然的)许多技术。你有没有把一张照片上传到你的Facebook账户,只是为了暗示给照片中的人贴上标签?Facebook正在使用神经网络来识别照片中的面孔。或者Siri呢?当你问你的iPhone关于今天的棒球成绩时,你的话语会用一种复杂的语音解析算法进行分析。如果没有深度学习,这一切都是不可能的。
机器学习是如何工作的?
注意所有对数学恐惧的读者:我很遗憾地告诉你,要完全理解大多数机器学习算法,就需要对一些关键的数学概念有一个基本的理解。但不要害怕!所需的概念很简单,并且借鉴了你可能已经上过的课程。机器学习使用线性代数、微积分、概率和统计。

Top 3线性代数概念:
1.矩阵运算;
2.特征值/特征向量;
3.向量空间和范数
Top 3微积分概念:
1.偏导数;
2.向量-值函数;
3.方向梯度
Top 3统计概念:
1.Bayes定理;
2.组合学;
3.抽样方法
一旦你对数学有了基本的理解,就该开始思考整个机器学习过程了。有五个主要步骤:
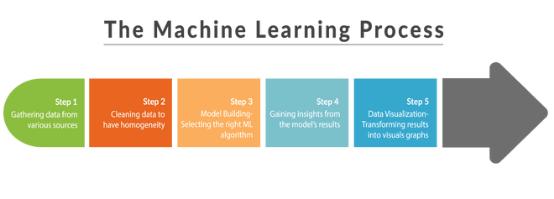
上面的图表以比较清楚的方式解释了步骤,所以在我们关注最关键的部分:为数据和情况选择正确的算法之前,花一分钟的时间来研究它。
We don’t have better algorithms, we just have more data.—Peter Norvig
让我们回顾一下算法的一些常见分组:
回归算法
这可能是最流行的机器学习算法,线性回归算法是基于连续变量预测特定结果的监督学习算法。另一方面,Logistic回归专门用来预测离散值。这两种(以及所有其他回归算法)都以它们的速度而闻名,它们一直是最快速的机器学习算法之一。
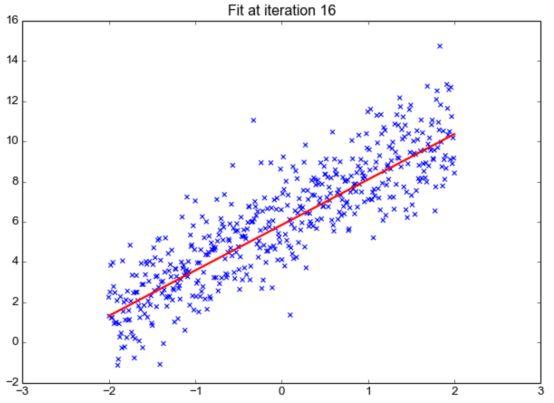
基于实例的算法
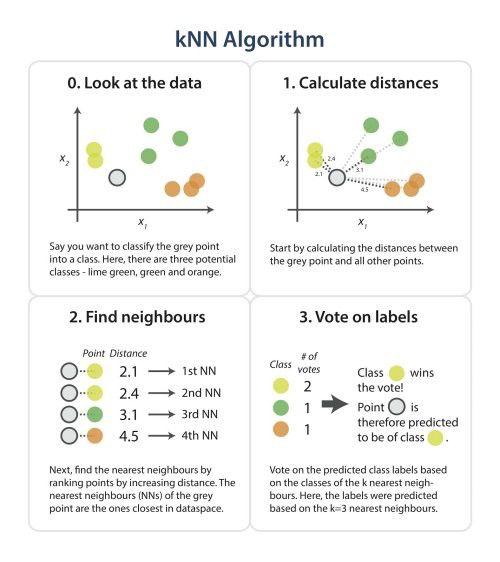
基于实例的分析使用提供数据的特定实例来预测结果。最著名的基于实例的算法是k-最近邻算法,也称为KNN。KNN用于分类,比较数据点的距离,并将每个点分配给它最接近的组。
决策树算法
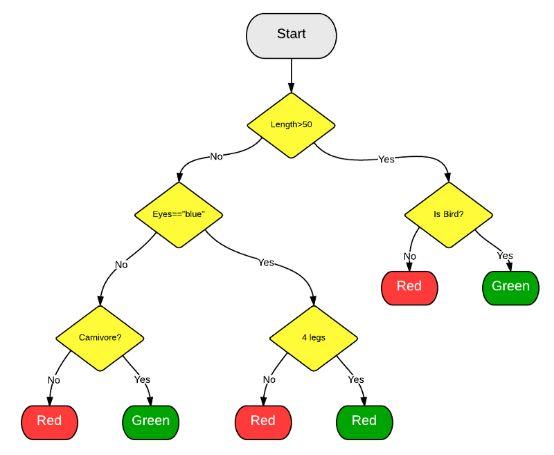
决策树算法将一组“弱”学习器集合在一起,形成一种强算法,这些学习器组织在树状结构中,相互分支。一种流行的决策树算法是随机森林算法。在该算法中,弱学习器是随机选择的,这往往可以获得一个强预测器。在下面的例子中,我们可以发现许多共同的特征(就像眼睛是蓝的或者不是蓝色的),它们都不足以单独识别动物。然而,当我们把所有这些观察结合在一起时,我们就能形成一个更完整的画面,并做出更准确的预测。
贝叶斯算法
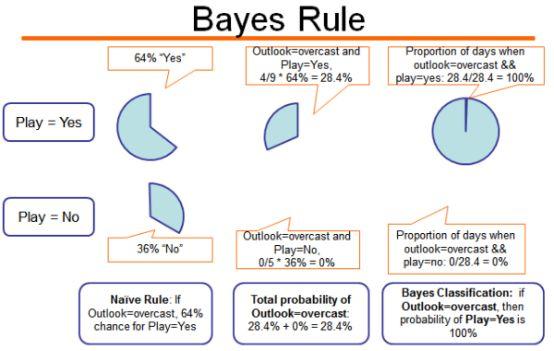
丝毫不奇怪,这些算法都是基于Bayes理论的,最流行的算法是朴素Bayes,它经常用于文本分析。例如,大多数垃圾邮件过滤器使用贝叶斯算法,它们使用用户输入的类标记数据来比较新数据并对其进行适当分类。
聚类算法
聚类算法的重点是发现元素之间的共性并对它们进行相应的分组,常用的聚类算法是k-means聚类算法。在k-means中,分析人员选择簇数(以变量k表示),并根据物理距离将元素分组为适当的聚类。
深度学习和神经网络算法
人工神经网络算法基于生物神经网络的结构,深度学习采用神经网络模型并对其进行更新。它们是大、且极其复杂的神经网络,使用少量的标记数据和更多的未标记数据。神经网络和深度学习有许多输入,它们经过几个隐藏层后才产生一个或多个输出。这些连接形成一个特定的循环,模仿人脑处理信息和建立逻辑连接的方式。此外,随着算法的运行,隐藏层往往变得更小、更细微。

其他算法
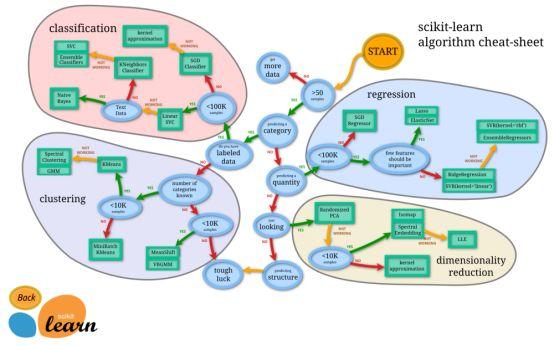
下面的图表是我发现的最好的图表,它展示了主要的机器学习算法、它们的分类以及它们之间的关系。
The numbers have no way of speaking for themselves. We speak for them. We imbue them with meaning….Before we demand more of our data, we need to demand more of ourselves.—Nate Silver
一旦你选择并运行了你的算法,还有一个非常重要的步骤:可视化和交流结果。虽然与算法编程的细节相比,这看起来既愚蠢又肤浅,但是良好的可视化是优秀数据科学家和伟大科学家的关键隔膜。如果没有人能够理解,那么惊人的洞察力又有什么用呢?
为什么机器学习很重要?
Just as electricity transformed almost everything 100 years ago, today I actually have a hard time thinking of an industry that I don’t think AI will transform in the next several years.— Andrew Ng
现在应该清楚的是,机器学习有巨大的潜力来改变和改善世界。通过像谷歌大脑和斯坦福机器学习小组这样的研究团队,我们正朝着真正的人工智能迈进一大步。但是,确切地说,什么是机器学习能产生影响的下一个主要领域?
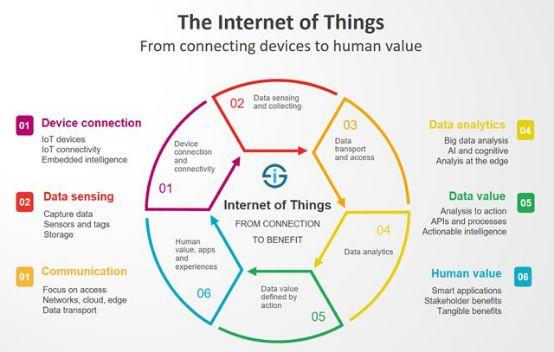
物联网
物联网(Internet of Things),或者说IOT,是指你家里和办公室里联网的物理设备。流行的物联网设备是智能灯泡,其销售额在过去几年里猛增。随着机器学习的进步,物联网设备比以往任何时候都更聪明、更复杂。机器学习有两个主要的与物联网相关的应用:使你的设备变得更好和收集你的数据。让设备变得更好是非常简单的:使用机器学习来个性化您的环境,比如,用面部识别软件来感知哪个是房间,并相应地调整温度和AC。收集数据更加简单,通过在你的家中保持网络连接的设备(如亚马逊回声)的通电和监听,像Amazon这样的公司收集关键的人口统计信息,将其传递给广告商,比如电视显示你正在观看的节目、你什么时候醒来或睡觉、有多少人住在你家。
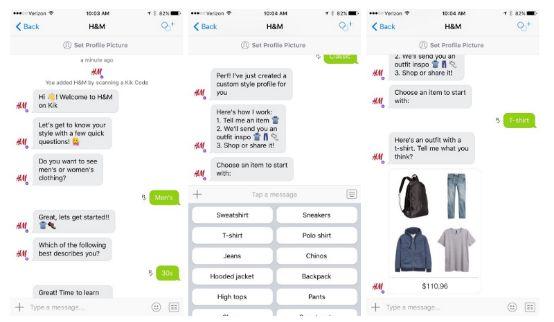
聊天机器人
在过去的几年里,我们看到了聊天机器人的激增,成熟的语言处理算法每天都在改进它们。聊天机器人被公司用在他们自己的移动应用程序和第三方应用上,比如Slack,以提供比传统的(人类)代表更快、更高效的虚拟客户服务。
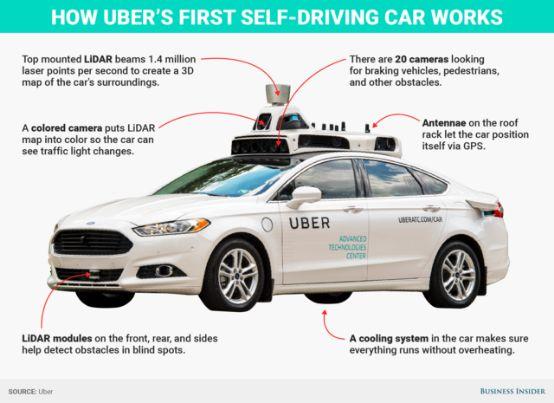
自动驾驶
我个人最喜欢的下一个大型机器学习项目是最远离广泛生产的项目之一。然而,目前有几家大型公司正在开发无人驾驶汽车,如雪佛兰、Uber和Tsla。这些汽车使用了通过机器学习实现导航、维护和安全程序的技术。一个例子是交通标志传感器,它使用监督学习算法来识别和解析交通标志,并将它们与一组标有标记的标准标志进行比较。这样,汽车就能看到停车标志,并认识到它实际上意味着停车,而不是转弯,单向或人行横道。
这就是我们进入机器学习世界的非常短暂的旅程。感谢观看。
图解十大经典机器学习算法入门
弱人工智能近几年取得了重大突破,悄然间,已经成为每个人生活中必不可少的一部分。以我们的智能手机为例,看看到底温藏着多少人工智能的神奇魔术。
下图是一部典型的智能手机上安装的一些常见应用程序,可能很多人都猜不到,人工智能技术已经是手机上很多应用程序的核心驱动力。

图1 智能手机上的相关应用
传统的机器学习算法包括决策树、聚类、贝叶斯分类、支持向量机、EM、Adaboost等等。这篇文章将对常用算法做常识性的介绍,没有代码,也没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的。
决策树
根据一些 feature(特征) 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
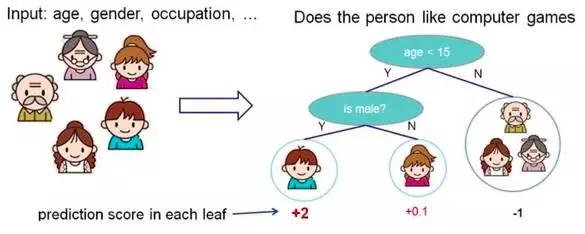
图2 决策树原理示意图
随机森林
在源数据中随机选取数据,组成几个子集:
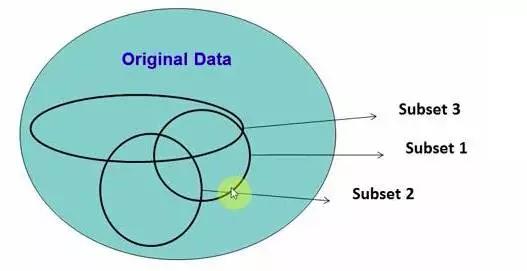
图3-1 随机森林原理示意图
S矩阵是源数据,有1-N条数据,A、B、C 是feature,最后一列C是类别:
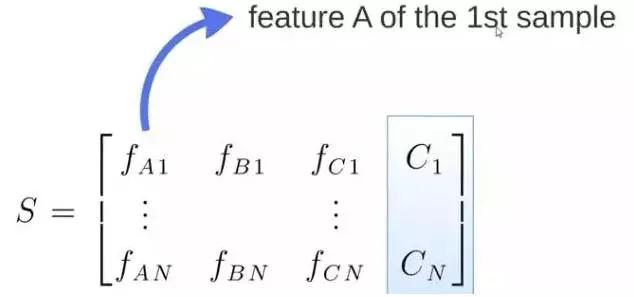
由S随机生成M个子矩阵:

这M个子集得到 M 个决策树:将新数据投入到这M个树中,得到M个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果。
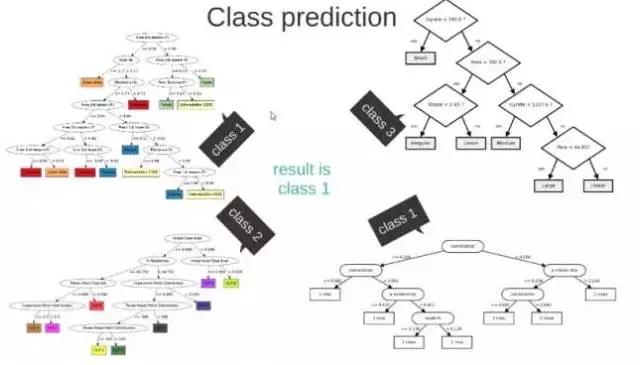
图3-2 随机森林效果展示图
逻辑回归
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
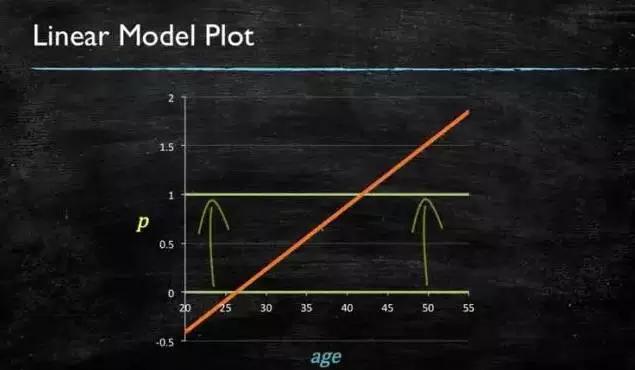
图4-1 线性模型图
所以此时需要这样的形状的模型会比较好:
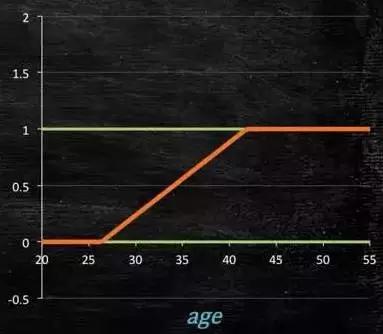
图4-2
那么怎么得到这样的模型呢?
这个模型需要满足两个条件 “大于等于0”,“小于等于1” 。大于等于0 的模型可以选择绝对值,平方值,这里用指数函数,一定大于0;小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了。

图4-3
再做一下变形,就得到了 logistic regressions 模型:

图4-4
通过源数据计算可以得到相应的系数了:

图4-5
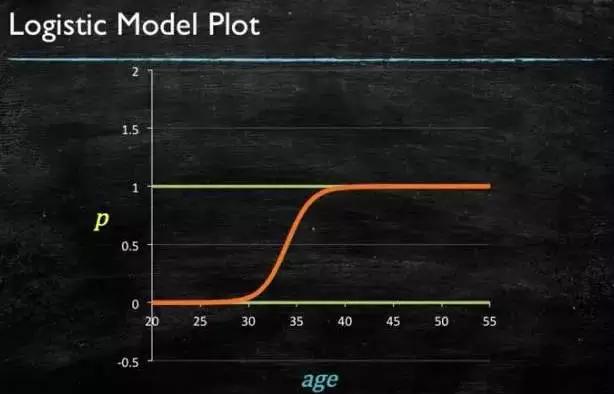
图4-6 LR模型曲线图
支持向量机
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好。
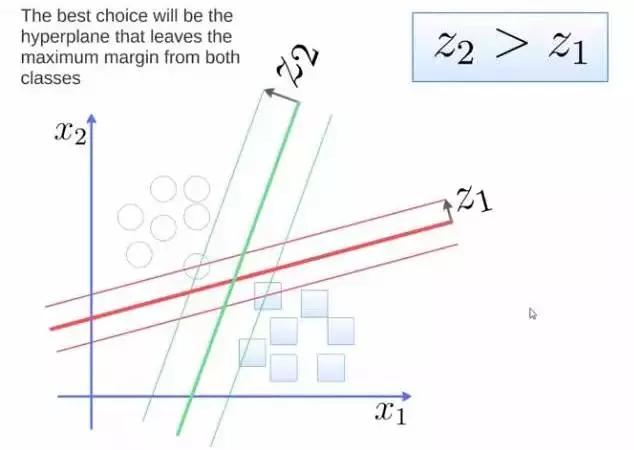
图5 分类问题示意图
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1:
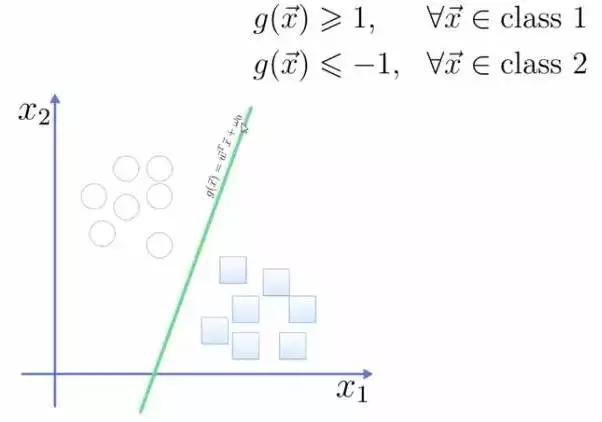
点到面的距离根据图中的公式计算:
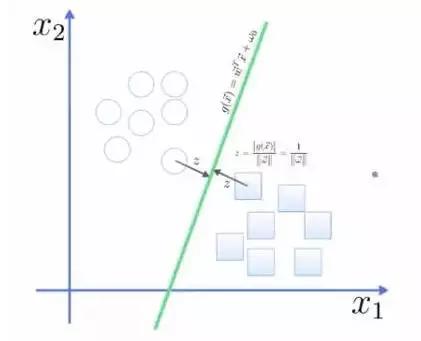
所以得到total margin的表达式如下,目标是最大化这个margin,就需要最小化分母,于是变成了一个优化问题:

举个例子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1):
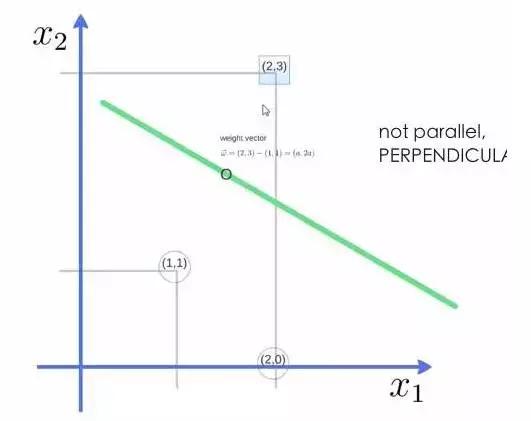
得到weight vector为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和 截矩 w0 的值,进而得到超平面的表达式。

a求出来后,代入(a,2a)得到的就是support vector,a和w0代入超平面的方程就是support vector machine。
朴素贝叶斯
举个在 NLP 的应用:给一段文字,返回情感分类,这段文字的态度是positive,还是negative:

图6-1 问题案例
为了解决这个问题,可以只看其中的一些单词:

这段文字,将仅由一些单词和它们的计数代表:
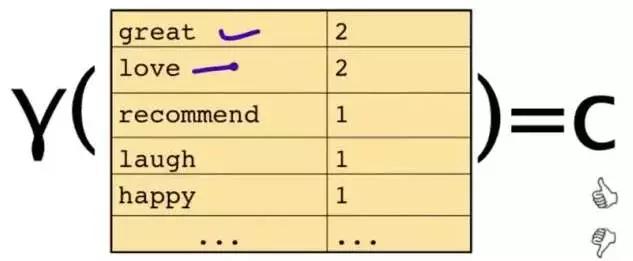
原始问题是:给你一句话,它属于哪一类 ?通过bayes rules变成一个比较简单容易求得的问题:
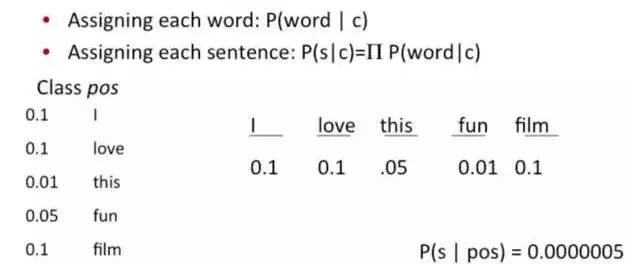
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率。例子:单词“love”在positive的情况下出现的概率是 0.1,在negative的情况下出现的概率是0.001。
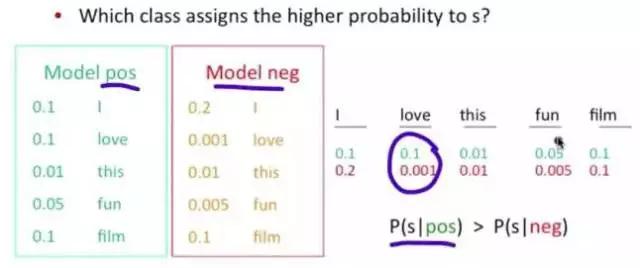
图6-2 NB算法结果展示图
K近邻算法
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类。
例子:要区分“猫”和“狗”,通过“claws”和“sound”两个feature来判断的话,圆形和三角形是已知分类的了,那么这个“star”代表的是哪一类呢?
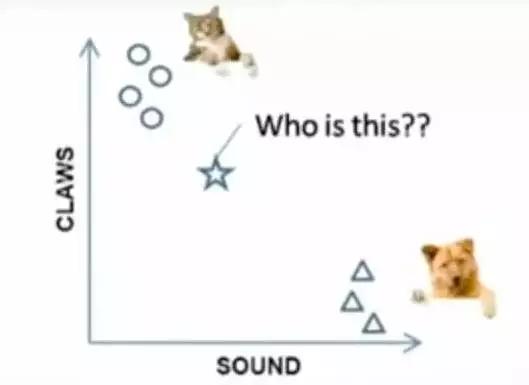
图7-1 问题案例
k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫。
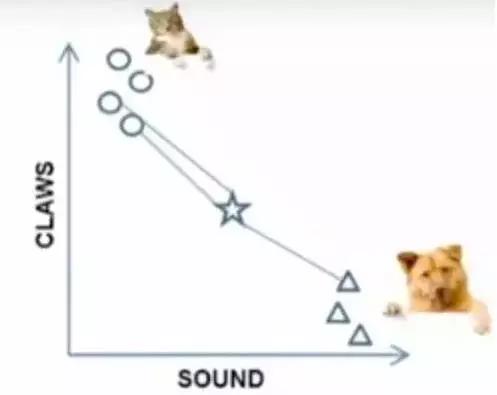
图7-2 算法步骤展示图
K均值算法
先要将一组数据,分为三类,粉色数值大,黄色数值小 。最开始先初始化,这里面选了最简单的 3,2,1 作为各类的初始值 。剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别。

图8-1 问题案例
分好类后,计算每一类的平均值,作为新一轮的中心点:

图8-2
几轮之后,分组不再变化了,就可以停止了:

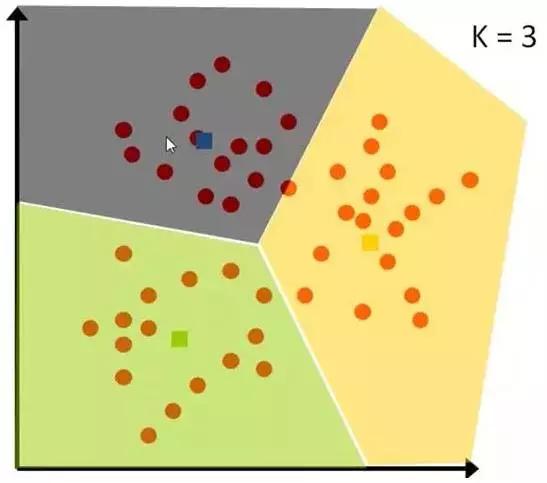
图8-3 算法结果展示
Adaboost
Adaboost 是 Boosting 的方法之一。Boosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度。

图9-1 算法原理展示
Adaboost 的例子,手写识别中,在画板上可以抓取到很多features(特征),例如始点的方向,始点和终点的距离等等。
图9-2
training的时候,会得到每个feature的weight(权重),例如2和3的开头部分很像,这个feature对分类起到的作用很小,它的权重也就会较小。

图9-3
而这个alpha角就具有很强的识别性,这个feature的权重就会较大,最后的预测结果是综合考虑这些feature的结果。

图9-4
神经网络
Neural Networks适合一个input可能落入至少两个类别里:NN由若干层神经元,和它们之间的联系组成。 第一层是input层,最后一层是output层。在hidden层和output层都有自己的classifier。
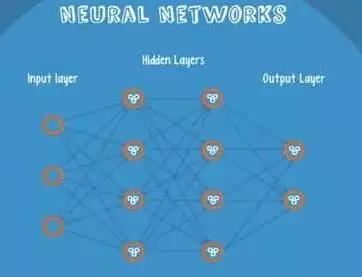
图10-1 神经网络结构
input输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output层的节点上的分数代表属于各类的分数,下图例子得到分类结果为class 1;同样的input被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和bias,这也就是forward propagation。

图10-2 算法结果展示
马尔科夫
Markov Chains由state(状态)和transitions(转移)组成。例子,根据这一句话 ‘the quick brown fox jumps over the lazy dog’,要得到markov chains。
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率。
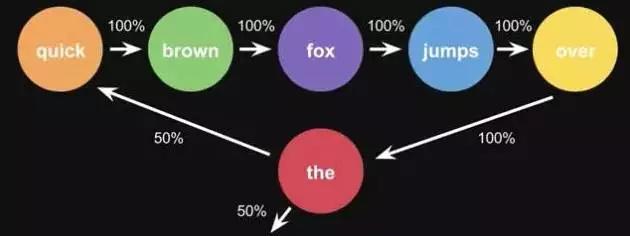
图11-1 马尔科夫原理图
这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如the后面可以连接的单词,及相应的概率。
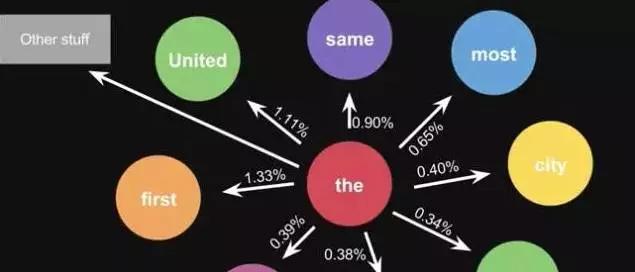
图11-2 算法结果展示
上述十大类机器学习算法是人工智能发展的践行者,即使在当下,依然在数据挖掘以及小样本的人工智能问题中被广泛使用。
