

导读:多亏了IPFS,这个非常真实、且非常容易使用的系统可能是我们实现更快、更民主的互联网的关键。如上所述,IPFS的基本思想是使用用户设备来存储、索引和交付当下需要驻留在集中式服务器上的数据。

让我们想象一下这样一个场景,你正在下载一个最新的meme文件,并耐心地在等待下载的完成。这个meme非常热门,所以你给你的朋友也发了一个链接。他们从你的手机中获取了文件,然后又开始与他们自己的朋友进行了分享。这样,meme文件便同时存储在了几十个设备当中,所以当一个新用户获得链接时,他们实际上最终会同时连接到其他多个人的设备上面,并从每个人那里获得一些片段,这使得下载几乎可以是即时的。
多亏了IPFS,这个非常真实、且非常容易使用的系统可能是我们实现更快、更民主的互联网的关键。如上所述,IPFS的基本思想是使用用户设备来存储、索引和交付当下需要驻留在集中式服务器上的数据。这听起来有点像是加密货币,没有错--这个项目的幕后推手Juan Benet曾将IPFS描述为“在某种意义上,IPFS对网站的影响……就像是比特币对货币的影响一样。”
什么是星际文件系统?
如果你知道BitTorrent或任何其他的P2P技术是如何工作的,那么你也可以很好地理解IPFS在做的事情。它可以在用户设备之间发送文件(包括构成大多数网站的HTML、CSS和JavaScript文件)和文件片段,就像你完全可以合法地下载公共领域的音乐一样。
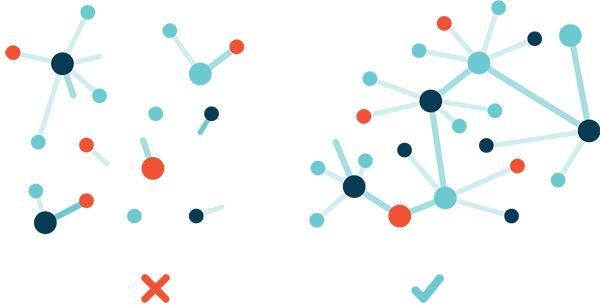
这意味着,你只需检查附近是否有人存储了页面(或其中的某些部分),而不是连接到服务器以查看站点。一旦你下载了这个页面,你的设备也会将其储存一段时间,这样其他人就可以从你这里获得它(或它的一部分)了。这听起来有点复杂,但实际上它比我们目前使用HTTP协议在单个服务器-客户端管道上发送数据的系统要高效得多。
为什么它是先进的?
与传统网络相比,IPFS有几个很大的优势:
更快、更高效的内容交付:你可以从地理位置相近的资源下载文件片段,从而最小化下载时间和带宽。
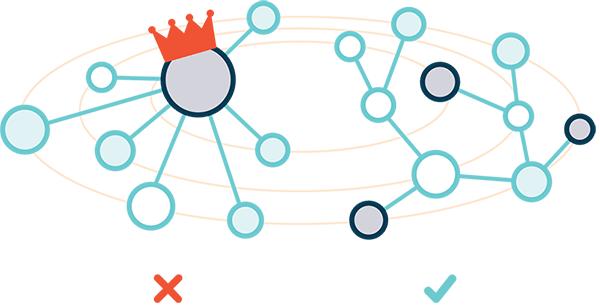
去中心化:没有一个单一的来源可以控制数据或控制对其的访问。

信息保存:由于没有单一的服务器会存储所有的数据,所以它不会像GeoCities网站那样就这么消失并带走你所有的数据。
在连接较差的地区,连接速度也会更快、更稳定:只要你想要的内容已经被下载到了某个你可以访问的地方,你就不需要进行长距离的连接,这对那些连接不稳定的地区来说非常有帮助。
审查的阻力:虽然还不完美,但总比集中式的模式更好。
工作原理:简短版
现在任何人都可以使用IPFS网络,因为它已经变得非常友好了。下面是一个简短的流程概述

当您将一个文件添加到IPFS中时,该文件会被分割为多个块,每个块都会通过一个算法分配得到一个惟一的ID。整个文件,包括这些块ID,也被分配了一个ID。最初,你的机器将是人们可以获取文件的惟一地方,但是其他节点(机器)也可以提取并分发文件。
如果网络注意到你的一些数据与已经存储在那里的内容相同,它只会使用这些数据而不是添加副本。假设你正在主持一张你录制的“豪华版”的专辑。其中10首歌曲与你已经录制的专辑相同,但其中两首是新的,因此当你将它们添加到IPFS时,系统将识别重复的歌曲并为它们使用现有的ID,而只为两首新歌添加新的ID。
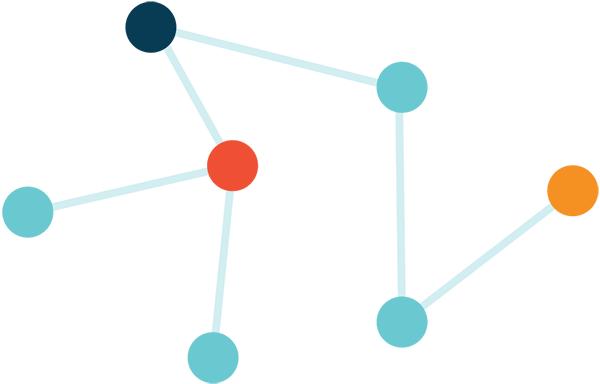
网络上的每个节点都会存储一些数据(可能是节点希望分发的数据,加上节点最近打开的数据)和一个索引的一部分,该索引能够帮助人们查找网络上的内容。
如果你想打开一个文件,你可以让网络查找它的ID并把你和它的拥有者联系起来。名为IPNS的命名系统有助于将人类可读的名字转换成系统可搜索的以及机器可读的ID。
更简单的一种描述是:IPFS能够为每个数据块提供一个名称,列出数据在任何给定时间的位置,并实现在设备之间直接发送数据。
工作原理:技术版
使IPFS起作用的主要有三件事:内容寻址模块给数据一个标识,Merkle-DAG给它一个结构,而分布式哈希表能够告诉你在哪里可以找到它。
内容寻址:告诉你是什么,而不是在哪里
我们当前的大多数内容都有其基于位置的地址(如C:/Users/Username/Documents, 192.124.249.3等)。这是在告诉我们去哪里找数据。这在分散的系统中是行不通的,因为内容可以存储在任何地方,所以像IPFS和BitTorrent这样的系统会使用“内容寻址”的方式。
内容寻址系统的工作原理是通过一种算法来为数据分配一个唯一的ID或哈希。每个相同的文件副本都会有相同的ID,这意味着当IPFS查找它时,它可以找到存储在网络上的每个实例。
Merkle-DAG:所有东西都有一个CID,它们都是相连接的
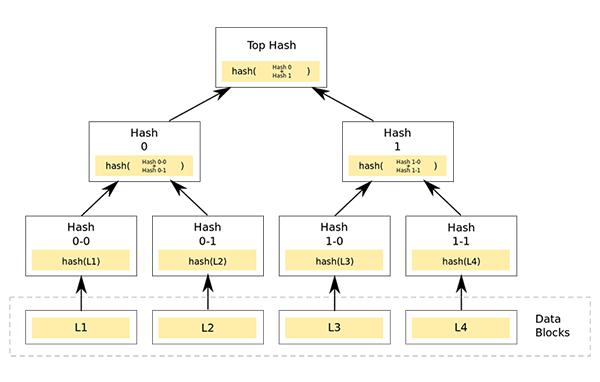
尽管听起来像一个德国政党,但Merkle-DAG(有向无环图)实际上是一种组织数据的方法。在这个系统中,每一块数据都有自己的内容ID(CID):文件夹、文件、文件内的数据块--所有的一切。这意味着可以将文件分成不同的部分、验证和重新组装。
IPFS文档将其描述为“海龟下面还是海龟”,因为所有内容都可以分解为一个由CID标识的数据集合。文件夹的CID将引导您到一个文件和文件夹CID的集合,其CID随后也将引导您到表示其他内容片段的其他CID,而它们也有自己的CID。任何文件中的任何更改都会导致其哈希和其文件夹的哈希的更改。
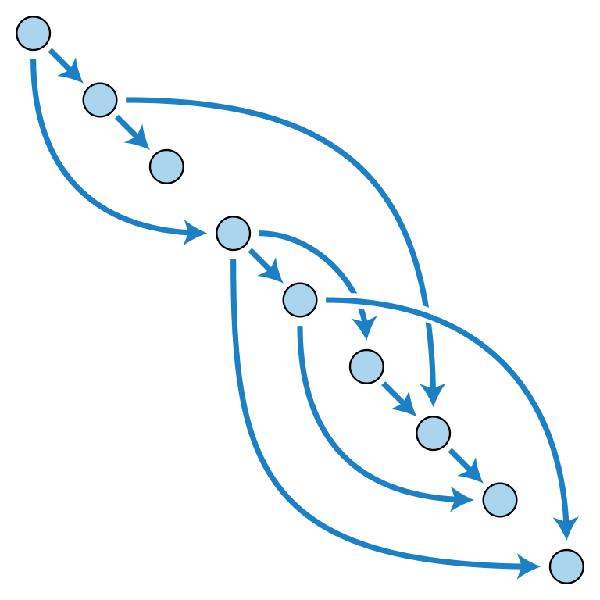
但是,数据实际上并不在这里,它只是告诉你在哪里可以找到所有的数据,以及一旦你有了数据,所有的数据应该如何组合在一起。从本质上说,是Merkle-DAG为所有这些ID提供了一个结构,非常类似于计算机上的文件系统。
分布式哈希表:IPFS定位内容的方式
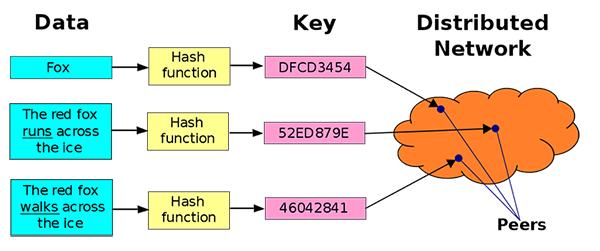
那么我们可以如何找到我们想要的数据呢?基本上,有一个大的数据库,它会将内容ID与承载该内容的计算机的位置相匹配,数据库本身也会被网络中的每个人分割。当您请求一块由CID表示的内容时,您的计算机将搜索CID,直到它找到了拥有它的人的列表。然后你的电脑将连接到这些人,下载你需要的东西,并把它们组装起来。这就是分布式哈希表--本质上是一个关于谁拥有什么东西的大列表。
IPFS很酷,但它会变得流行吗?
IPFS始于2015年,自那以后已经取得了快速的发展。已经有数十个应用程序和网站建立在它之上(包括分散的YouTube,或DTube),一个区块链文件存储系统(Filecoin),和一个GeoCities的替代品(Neocities)。它成功地将去中心化和用户友好性结合在了一起,这可能就是为什么它成为了所有想要实现去中心化的项目的首选,比如Sociall(一个去中心化的社交网络)和Brave。
Cloudflare的IPFS网关已经大受欢迎,网络的使用也变得越来越容易了;你所要做的就是下载一个程序并安装一个浏览器扩展。当然,对于它是否真的是最好的解决方案依然存在争议--它也远非是唯一一个有同样愿景的项目--但它也还没有显示出任何可能放缓的迹象。即使它不能完全取代HTTP,它也肯定会成为下一个版本的Internet的一部分。
原文标题:How the Interplanetary File System (IPFS) Could Decentralize the Web,作者:Andrew Braun
